MMMU
MMMU
‼️[2026-02-12] We have released the answers for the MMMU test set! You can now evaluate your models on the test set locally! 🎉
🔥[2024-09-05] Introducing MMMU-Pro, a robust version of MMMU benchmark for multimodal AI evaluation! 🚀
🚀[2024-01-31]: We added Human Expert performance on the Leaderboard!🌟
🔥[2023-12-04]: Our evaluation server for the test set is now available on EvalAI. We welcome all submissions and look forward to your participation! 😆
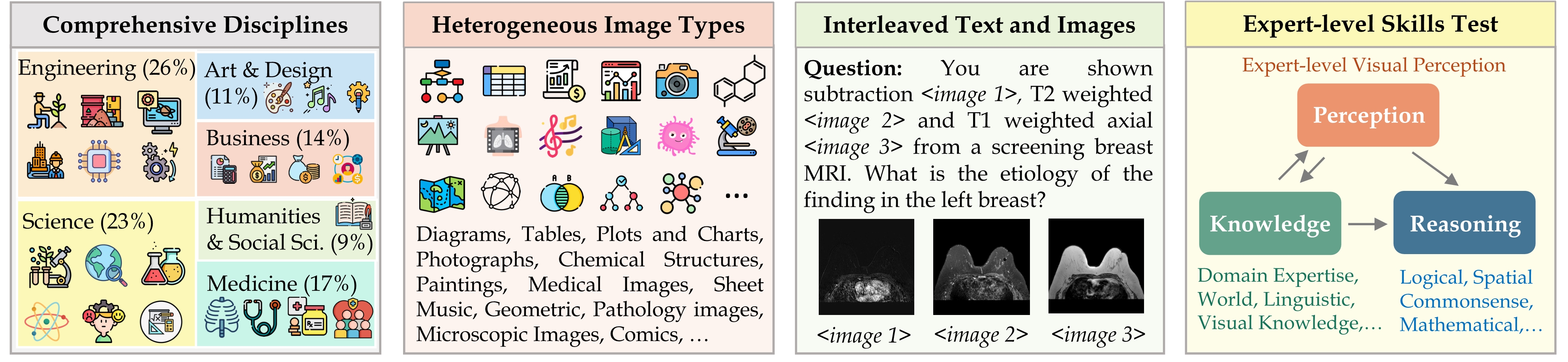
We introduce MMMU: a new benchmark designed to evaluate multimodal models on massive multi-discipline tasks demanding college-level subject knowledge and deliberate reasoning. MMMU includes 11.5K meticulously collected multimodal questions from college exams, quizzes, and textbooks, covering six core disciplines: Art & Design, Business, Science, Health & Medicine, Humanities & Social Science, and Tech & Engineering. These questions span 30 subjects and 183 subfields, comprising 30 highly heterogeneous image types, such as charts, diagrams, maps, tables, music sheets, and chemical structures. Unlike existing benchmarks, MMMU focuses on advanced perception and reasoning with domain-specific knowledge, challenging models to perform tasks akin to those faced by experts. Our evaluation of 14 open-source LMMs and the proprietary GPT-4V(ision) highlights the substantial challenges posed by MMMU. Even the advanced GPT-4V only achieves a 56% accuracy, indicating significant room for improvement. We believe MMMU will stimulate the community to build next-generation multimodal foundation models towards expert artificial general intelligence.
MMMU Benchmark
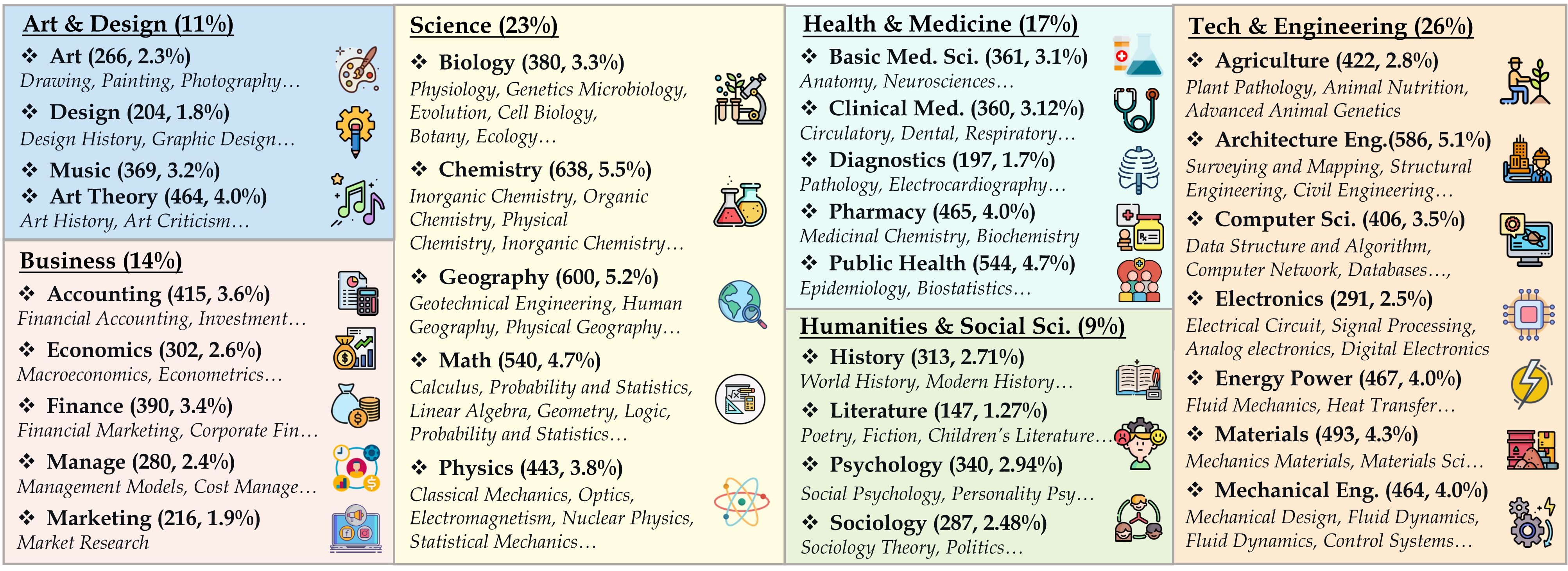
We introduce the Massive Multi-discipline Multimodal Understanding and Reasoning (MMMU) benchmark, a novel benchmark meticulously curated to assess the expert-level multimodal understanding capability of foundation models across a broad scope of tasks. Covering subjects across disciplines, including Art, Business, Health & Medicine, Science, Humanities & Social Science, and Tech & Engineering, and over subfields. The detailed subject coverage and statistics are detailed in the figure. The questions in our benchmark were manually collected by a team of college students (including coauthors) from various disciplines and subjects, drawing from online sources, textbooks, and lecture materials.

MMMU is designed to measure three essential skills in LMMs: perception, knowledge, and reasoning. Our aim is to evaluate how well these models can not only perceive and understand information across different modalities but also apply reasoning with subject-specific knowledge to derive the solution.
Our MMMU benchmark introduces key challenges to multimodal foundation models, as detailed in a figure. Among these, we particularly highlight the challenge stemming from the requirement for both expert-level visual perceptual abilities and deliberate reasoning with subject-specific knowledge. This challenge is vividly illustrated through our tasks, which not only demand the processing of various heterogeneous image types but also necessitate a model's adeptness in using domain-specific knowledge to deeply understand both the text and images and to reason. This goes significantly beyond basic visual perception, calling for an advanced approach that integrates advanced multimodal analysis with domain-specific knowledge.
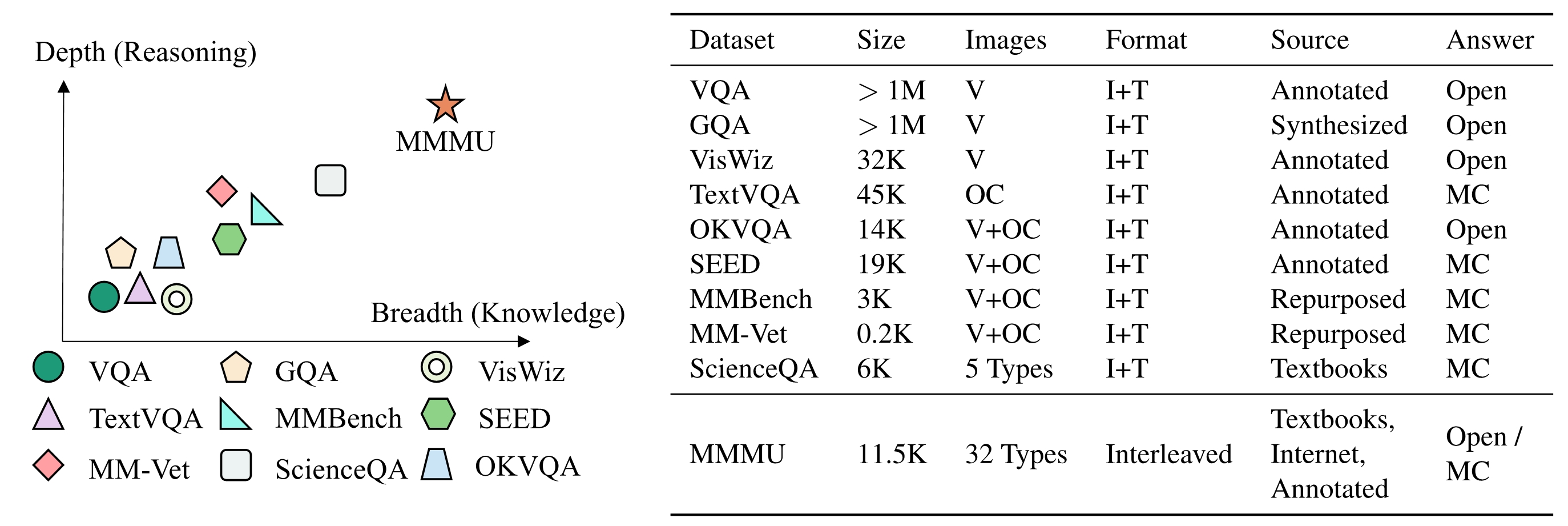
To further distinguish the difference between dataset and other existing ones, we elaborate the benchmark details in Figure. From the breadth perspective, the prior benchmarks are heavily focused on daily knowledge and common sense. The covered image format is also limited. Our benchmark aims to cover college-level knowledge with 30 image formats including diagrams, tables, charts, chemical structures, photos, paintings, geometric shapes, music sheets, medical images, etc. In the depth aspect, the previous benchmarks normally require commonsense knowledge or simple physical or temporal reasoning. In contrast, our benchmark requires deliberate reasoning with college-level subject knowledge.
Sampled MMMU examples from each discipline. The questions and images need expert-level knowledge to understand and reason.
Sampled MMMU examples from each discipline. The questions and images need expert-level knowledge to understand and reason.
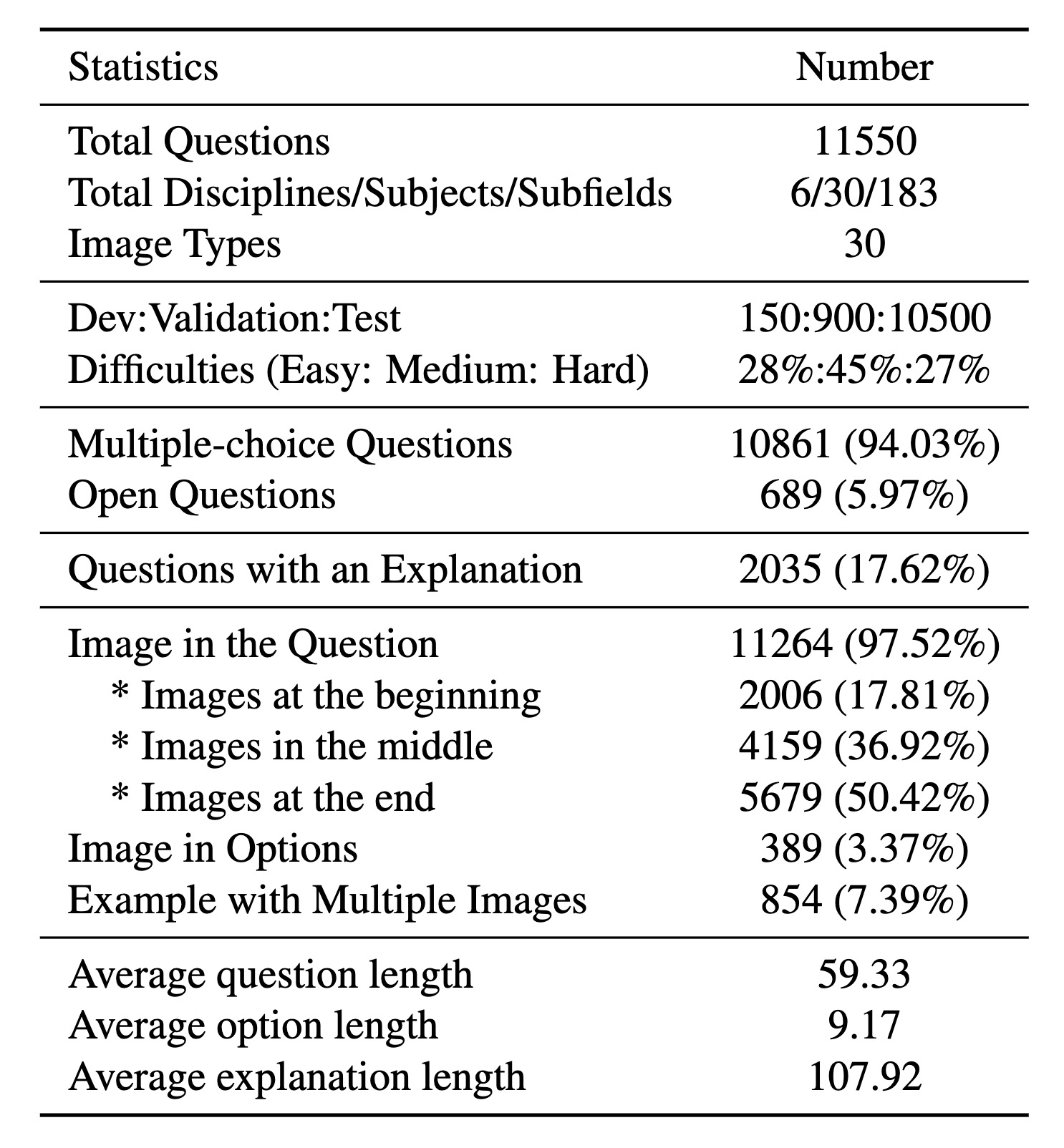
Key statistics of the MMMU benchmark
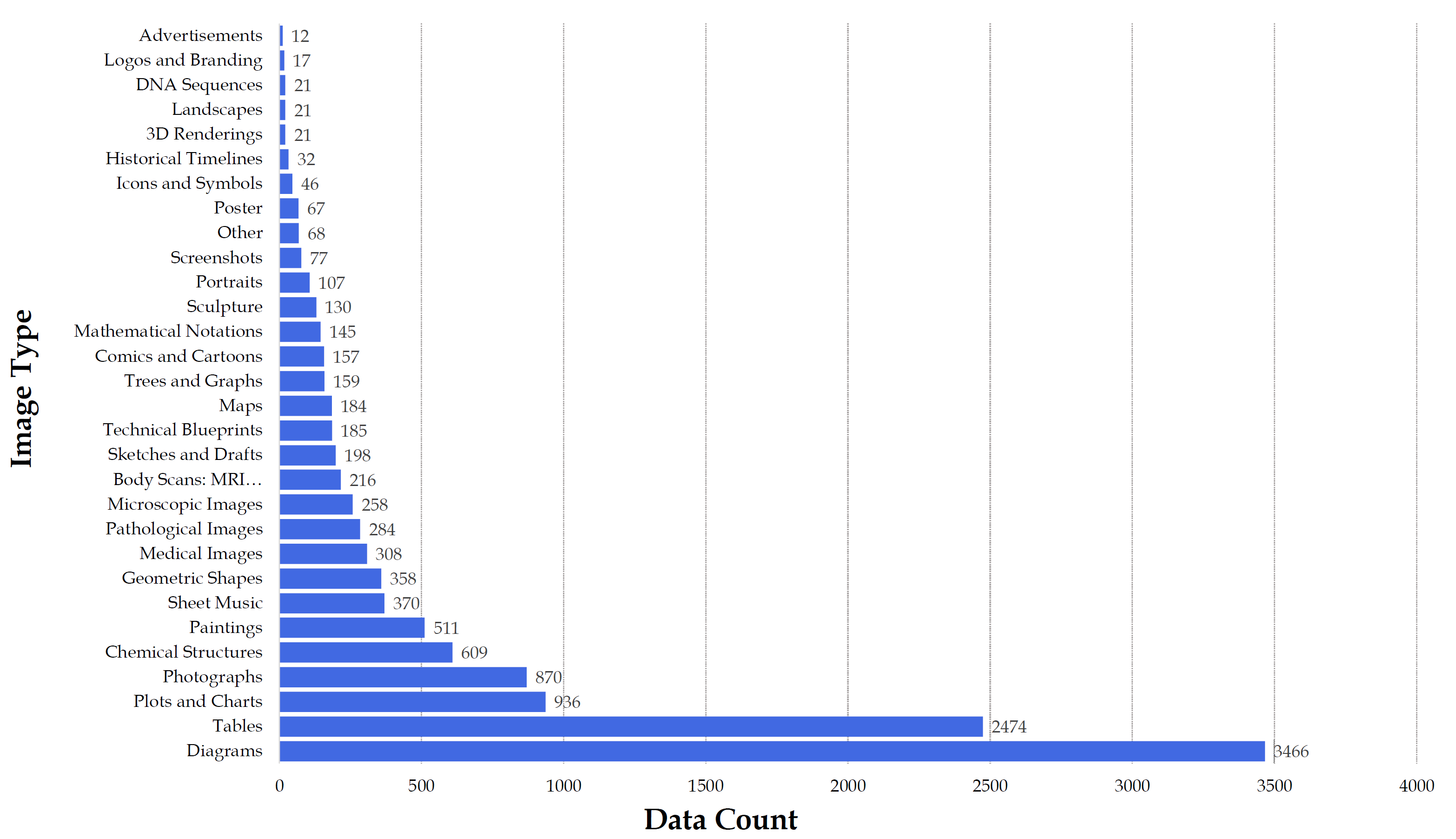
Distribution of image types in the MMMU dataset
We evaluate various models including LLMs and LMMs. In each type, we consider both closed- and open-source models. Our evaluation is conducted under a zero-shot setting to assess the capability of models to generate accurate answers without fine-tuning or few-shot demonstrations on our benchmark. For all models, we use the default prompt provided by each model for multi-choice or open QA, if available. If models do not provide prompts for task types in MMMU, we conduct prompt engineering on the validation set and use the most effective prompt for the later zero-shot experiment.
Click on MMMU-Pro, MMMU (Val) or MMMU (Test) to expand detailed results.
Last updated: 09/05/2025
| Reset | MMMU-Pro | MMMU(Val) | MMMU(Test) | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Name | Size | Date | Overall | Vision | Standard | Overall | Art & Design | Business | Science | Health & Medicine | Human. & Social Sci. | Tech & Eng. | Overall | Art & Design | Business | Science | Health & Medicine | Human. & Social Sci. | Tech & Eng. |
Overall results of different models on the MMMU leaderboard. The best-performing model in each category is in-bold, and the second best is underlined. *: results provided by the authors.
We compare the performance of various models across top frequent image types. Across all types, GPT-4V consistently outperforms the other models by a huge margin. Open-source models demonstrate relatively strong performance in categories like Photos and Paintings, which are more frequently seen during training. However, for less common image categories like Geometric shapes, Music sheets and Chemical structures, all models obtain very low scores (some are close to random guesses). This indicates that the existing models are generalizing poorly towards these image types.
Diagrams (3184)
Tables (2267)
Plots and Charts (840)
Chemical Structures (573)
Photographs (770)
Paintings (453)
Geometric Shapes (336)
Sheet Music (335)
Medical Images (272)
Pathological Images (253)
Microscopic Images (226)
MRI, CT scans, and X-rays (198)
Sketches and Drafts (184)
Maps (170)
Technical Blueprints (162)
Trees and Graphs (146)
Mathematical Notations (133)
Comics and Cartoons (131)
Sculpture (117)
Portraits (91)
Screenshots (70)
Other(60)
Poster(57)
Icons and Symbols (42)
Historical Timelines (30)
3D Renderings (21)
DNA Sequences (20)
Landscapes (16)
Logos and Branding(14)
Advertisements (10)
Selected models' performance on 30 different image types. Note that a single image may have multiple image types.
we compares the performance of selected models across three difficulty levels. GPT-4V demonstrates a significantly higher proficiency, with a success rate of 76.1%, compared to opensource models in the “Easy” category. When it comes to the “Medium” category, while the gap narrows, GPT-4V still leads at 55.6%. The further diminishing performance gap in the “Hard” category across models indicates that as the complexity of tasks increases, the advantage of more advanced models like GPT-4V almost disappears. This might reflect a current limitation in handling expert-level challenging queries even for the most advanced models.
Click legend to switch the comparison chart.
Result decomposition across question difficulty levels.
Click legend to switch the comparison chart.
Result decomposition across single image and multiple image tasks.
We delve into the analysis of errors by GPT-4V, a pivotal aspect for understanding its operational capabilities and limitations. This analysis serves not only to identify the model's current shortcomings but also to guide future enhancements in its design and training. We meticulously examine 150 randomly sampled error instances from GPT-4V's predictions. These instances are analyzed by expert annotators who identify the root causes of mispredictions based on their knowledge and the golden explanations if available. The distribution of these errors is illustrated in Figure, and a selection of 100 notable cases, along with detailed analyses, is included in the Appendix.

Error distribution over 150 annotated GPT-4V errors.
@inproceedings{yue2023mmmu,
title={MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI},
author={Xiang Yue and Yuansheng Ni and Kai Zhang and Tianyu Zheng and Ruoqi Liu and Ge Zhang and Samuel Stevens and Dongfu Jiang and Weiming Ren and Yuxuan Sun and Cong Wei and Botao Yu and Ruibin Yuan and Renliang Sun and Ming Yin and Boyuan Zheng and Zhenzhu Yang and Yibo Liu and Wenhao Huang and Huan Sun and Yu Su and Wenhu Chen},
booktitle={Proceedings of CVPR},
year={2024},
}